Статья №392

Многие страницы никогда не индексируются Google. Узнайте, почему почему Гугл не индексирует страницы сайта. Но сначала подпишитесь на наш Телеграм. Там мы публикуем идеи, которыми больше нигде не делимся. Мы разрабатываем сайты. Знаем, как запустить рост сайта с первых дней. Продвигаем сайты. Делаем продажи с первых дней запуска сайта. Свяжитесь с нами!
Не все страницы вашего сайта светятся в Google
Если вы работаете с сайтом, особенно с большим, вы, вероятно, заметили, что не все страницы вашего сайта индексируется. Почему Google пишет: «страница просканирована, но пока не проиндексирована указанные ниже страницы не индексируются Google и не появляются в результатах поиска»? Причин может быть несколько.
Многие seo-оптимизаторы по-прежнему считают, что Google не может индексировать контент из-за технических особенностей, но это миф. Правда в том, что Google может не проиндексировать ваши страницы, если вы не отправляете последовательные технические сигналы о том, какие страницы вы хотите проиндексировать.
Что касается других технических проблем: такие вещи, как JavaScript, действительно усложняют индексацию, ваш сайт может страдать от серьезных проблем с индексированием, даже если он написан на чистом HTML.
Причины, по которым Google не индексирует ваши страницы
Проверив самые популярные интернет-магазины мира, обнаружили, что в среднем 15% их индексируемых страниц продуктов невозможно найти в Google.
Результат удивительный. Почему? Каковы причины, по которым Google решает не индексировать то, что технически должно быть проиндексировано?
Консоль поиска Google сообщает о нескольких статусах неиндексированных страниц, например «Просканировано — в настоящее время не проиндексировано» или «Обнаружено — в настоящее время не проиндексировано». Хотя эта информация явно не помогает решить проблему, это хорошее начала диагностики.
Основные проблемы с индексацией
Наиболее популярные проблемы индексации, о которых сообщает Google Search Console:
1. «Просканировано — в настоящее время не проиндексировано»
В этом случае Google посетил страницу, но не проиндексировал ее.
Исходя из моего опыта, это обычно проблема качества контента. Учитывая бум электронной коммерции, который в настоящее время происходит, ожидаемо, что Google стал более требовательным к качеству сайтов. Поэтому, если вы заметили, что ваши страницы «просканированы — в настоящее время не проиндексированы», убедитесь, что контент на этих страницах имеет уникальную ценность:
- Используйте уникальные заголовки, описания и текст на всех индексируемых страницах.
- Избегайте копирования описаний продуктов из внешних источников.
- Используйте канонические теги для объединения повторяющегося контента.
- Запретите Google сканировать или индексировать некачественные разделы вашего сайта с помощью файла robots.txt или тега noindex.
Мы разрабатываем рейтинговые сайты. Напишите нам!
2. «Обнаружено — в настоящее время не индексируется»
Это проблема может охватывать всё, от проблем со сканированием до недостаточного качества контента. Это серьезная проблема, особенно в случае крупных интернет-магазинов. И такое может случиться с десятками миллионов URL-адресов на одном сайте.
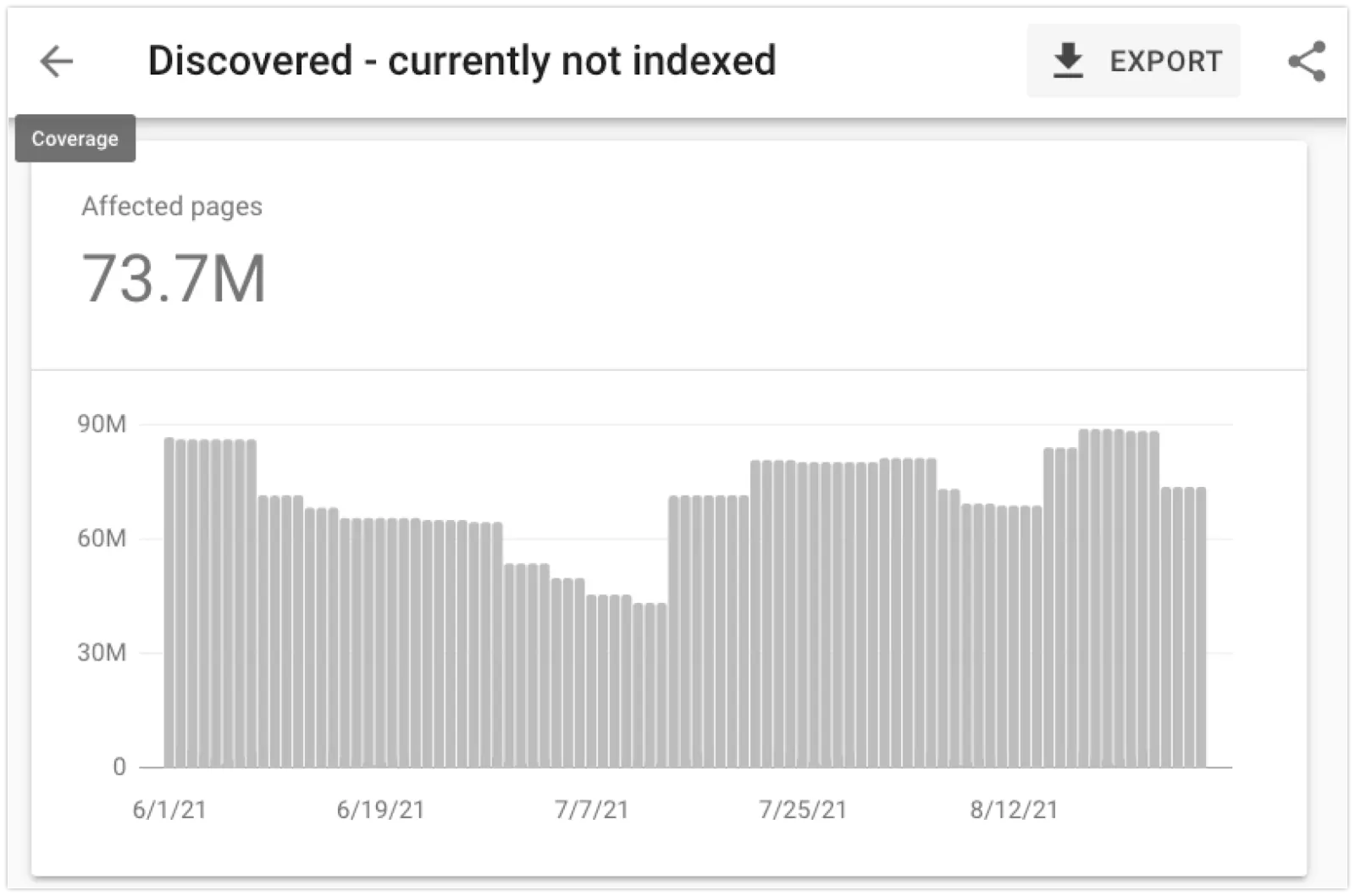
Google может сообщить, что страницы продуктов электронной коммерции «обнаружены — в настоящее время не проиндексированы» по следующим причинам:
- Проблема с бюджетом сканирования: в очереди сканирования может быть слишком много URL-адресов, и они могут быть просканированы и проиндексированы позже.
- Проблема с качеством: Google может подумать, что некоторые страницы в этом домене не стоит сканировать и решит не посещать их, ища шаблон в их URL.
Чтобы справиться с этой проблемой, требуется некоторый опыт. Если вы обнаружите, что ваши страницы «обнаружены — в настоящее время не проиндексированы», сделайте следующее:
- Определите, есть ли шаблоны страниц, попадающих в эту категорию. Может быть, проблема связана с определенной категорией товаров, а вся категория не имеет внутренней связи? Или, может быть, огромная часть страниц продуктов ожидает в очереди на индексирование?
- Оптимизируйте свой краулинговый бюджет. Сосредоточьтесь на обнаружении некачественных страниц, которые Google тратит много времени на сканирование. К обычным подозрениям относятся страницы отфильтрованных категорий и страницы внутреннего поиска — эти страницы могут легко попасть в десятки миллионов на типичном сайте электронной коммерции. Если робот Googlebot может свободно их сканировать, у него может не быть ресурсов для доступа к ценным материалам на вашем сайте, проиндексированным в Google.
Мы разрабатываем сайты под ключ и продвигаем их статьями. Напишите нам!
3. «Повторяющееся содержание»
Дублирование контента может быть вызвано разными причинами, например:
- Варианты языка (например, английский язык в Великобритании, США или Канаде). Если у вас есть несколько версий одной и той же страницы, ориентированных на разные страны, некоторые из этих страниц могут оказаться неиндексированными.
- Дублированный контент, используемый вашими конкурентами. Это часто происходит в e-commerce, когда несколько сайтов используют одно и то же описание продукта, предоставленное производителем.
Помимо использования rel = canonical, 301 редиректа или создания уникального контента, я бы сосредоточился на предоставлении уникальной ценности для пользователей. Fast-growing-trees.com может быть примером. Вместо скучных описаний и советов по посадке и поливу на сайте можно увидеть подробный FAQ по многим продуктам.
Кроме того, вы можете легко сравнивать похожие товары.
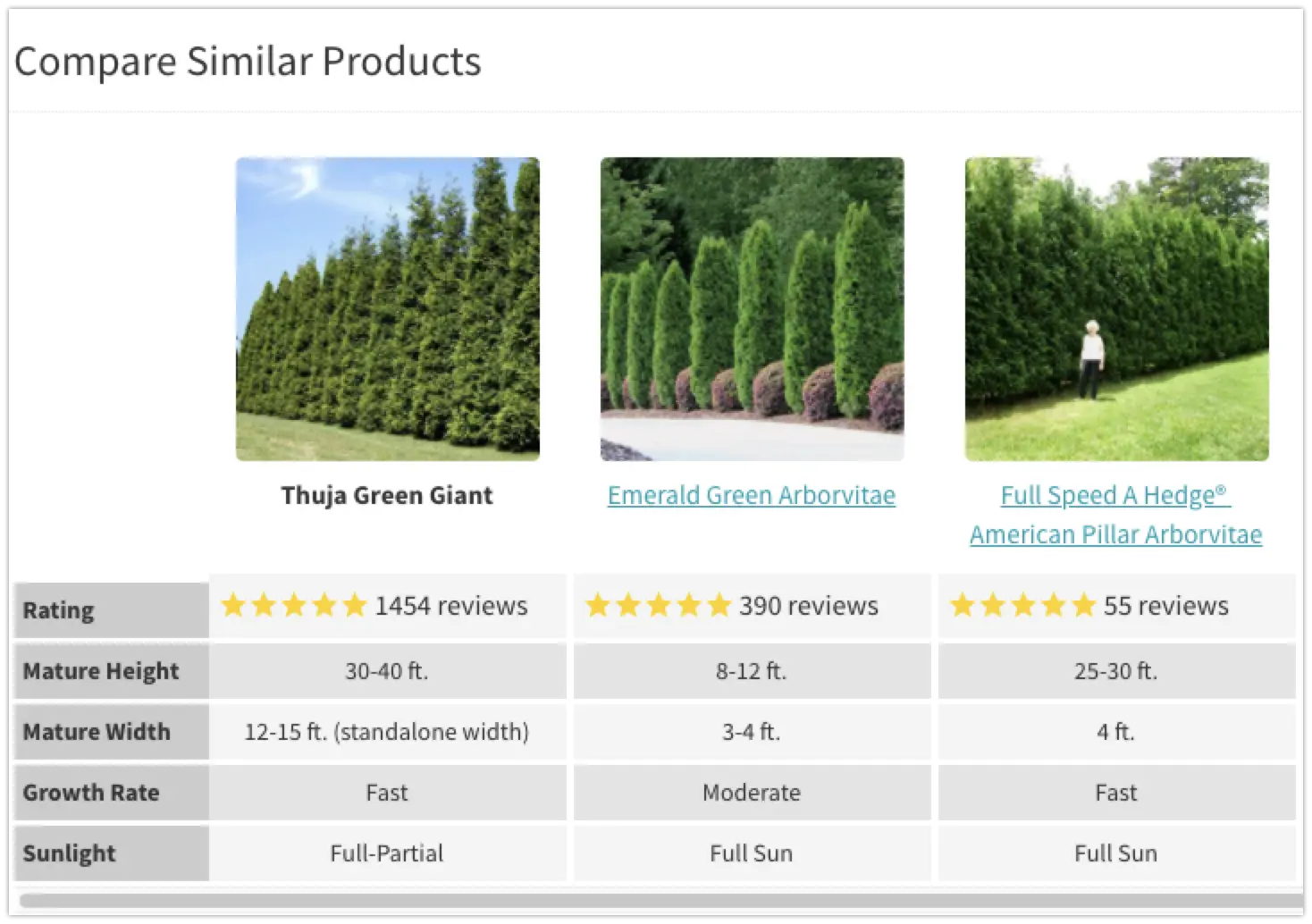
Для многих продуктов есть FAQ.
Как проверить индексирование вашего сайта
Вы можете легко проверить, сколько страниц вашего сайта не проиндексировано, открыв отчет об индексировании в Google Search Console.
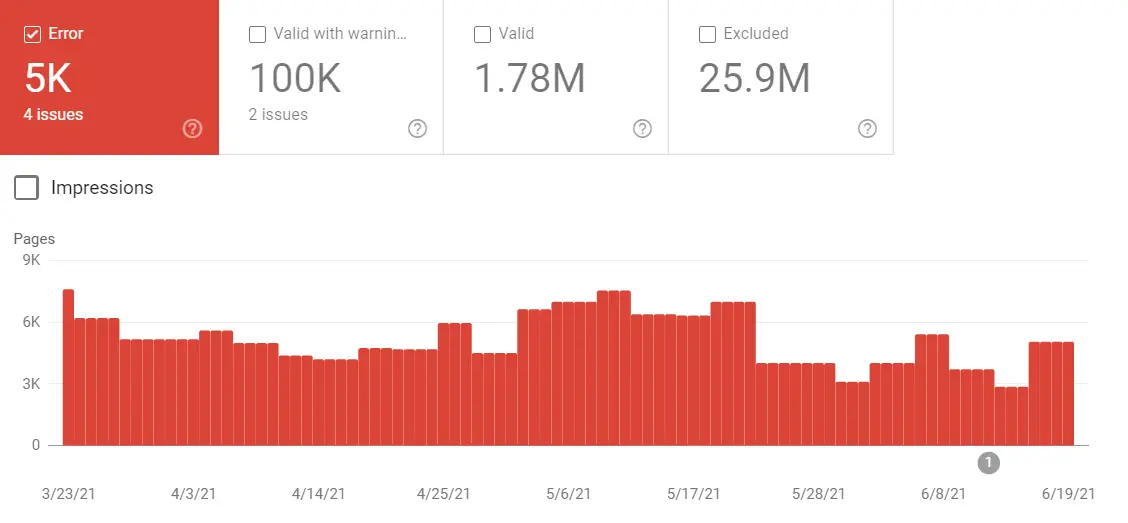
Первое, на что следует обратить внимание, — это количество исключенных страниц. Затем попробуйте найти закономерность — какие типы страниц не индексируются?
Если у вас интернет-магазин, вы, скорее всего, увидите неиндексированные страницы продуктов. Хотя это всегда должно быть предупреждающим знаком, вы не можете ожидать, что все страницы ваших продуктов будут проиндексированы, особенно на большом сайте. Например, в большом интернет-магазине обязательно будут дублирующиеся страницы и товары с истекшим сроком годности или отсутствующие в наличии. Этим страницам может не хватать качества, которое поместило бы их в начало очереди индексации Google (и это если Google вообще решит сканировать эти страницы).
Кроме того, на крупных интернет-магазинах, как правило, возникают проблемы с бюджетом сканирования. Я видел случаи, когда в интернет-магазинах было более миллиона товаров, в то время как 90% из них были классифицированы как «обнаруженные — в настоящее время не проиндексированные». Но если вы видите, что важные страницы исключаются из индекса Google, вы должны быть серьезно обеспокоены.
Мы экспертно запускаем сайты брендов. Напишите нам!
Как повысить вероятность того, что Google проиндексирует ваши страницы
Каждый сайт индивидуален и может иметь разные проблемы с индексированием. Тем не менее, вот советы, как проиндексировать сайт:
1. Избегайте ошибок «Soft 404».
Убедитесь, что на ваших страницах нет ничего, что может ложно указывать на мягкий статус 404. Это включает в себя все, что угодно, от использования «Не найдено» или «Недоступно» в копии до наличия числа «404» в URL-адресе.
2. Используйте внутренние ссылки.
Внутренние ссылки — один из ключевых сигналов для Google о том, что данная страница является важной частью сайта и заслуживает индексации. Не оставляйте лишних страниц в структуре вашего сайта и не забудьте включить все индексируемые страницы в карты сайта. Внутренние ссылки — один из элементов кайдзен сайта.
3. Реализуйте надежную стратегию сканирования.
Не позволяйте Google сканировать ваш сайт. Если на сканирование менее ценных частей вашего домена тратится слишком много ресурсов, Google может потребоваться слишком много времени, чтобы добраться до нужного. Анализ журнала сервера может дать вам полное представление о том, что сканирует робот Googlebot и как его оптимизировать.
4. Устранение некачественного и дублированного контента.
На каждом большом сайте в конечном итоге появляются страницы, которые не следует индексировать. Убедитесь, что эти страницы не попадают в ваши карты сайта, и при необходимости используйте тег noindex и файл robots.txt. Если вы позволите Google проводить слишком много времени в худших частях вашего сайта, это может недооценить общее качество вашего домена.
5. Посылайте последовательные сигналы SEO.
Один из распространенных примеров отправки непоследовательных сигналов SEO в Google — это изменение канонических тегов с помощью JavaScript. Как сказал Мартин Сплитт из Google во время работы JavaScript SEO Office Hours, вы никогда не можете быть уверены в том, что Google будет делать, если у вас есть один канонический тег в исходном HTML и другой после рендеринга JavaScript.
Мы виртуозно делаем запоминающиеся сайты. Напишите нам!
Интернет становится слишком большим
За последние пару лет Google совершил гигантский скачок в обработке JavaScript, упростив работу оптимизаторов поисковых систем. В наши дни реже можно увидеть сайты на базе JavaScript, которые не индексируются из-за конкретного технического стека, который они используют.
Но можем ли мы ожидать того же самого с проблемами индексации, не связанными с JavaScript? Я так не думаю. Интернет постоянно растет. Каждый день появляются новые сайты, а существующие растут. Сможет ли Google справиться с этой проблемой?
Этот вопрос появляется время от времени. Цитата Google:
«У Google ограниченное количество ресурсов, поэтому, когда он сталкивается с почти бесконечным количеством контента, доступного в Интернете, робот Googlebot может найти и просканировать только часть этого контента. Затем из просканированного контента мы можем проиндексировать только его часть».
Другими словами, Google может посещать только часть всех страниц в Интернете и индексировать еще меньшую часть. И даже если ваш сайт великолепен, вы должны помнить об этом.
Вероятно, Google не будет посещать все страницы вашего сайта, даже если он относительно небольшой. Ваша задача — убедиться, что Google может обнаруживать и индексировать страницы, важные для вашего бизнеса.
Мы продвигаем сайты статьями. Свяжитесь с нами!
По теме:
Делаем сайт, максимально дружелюбный для SEO — чек-лист
Почему не проиндексирована главная страница сайта: объясняет Google
Узнай какие SEO-факторы рулят: данные из слива Яндекса!
Google Search Console: что это такое? Как настроить и использовать GSC — руководство на 2023-й.
Какие 5 ошибок убивают ваше SEO
Что ждёт ваш сайт, когда Google раскачает непрерывную страницу выдачи
РАЗВЕРНУТЬ СТАТЬИ ПО ТЕМЕ
 Продвижение
ПродвижениеЧто такое Экспертный Блог и как он увеличивает прибыль
8819 0 Продвижение
ПродвижениеФундаментальное SEO-продвижение
5921 0

Д
е
й
с
т
в
у
й
!
Оставьте ваши контакты и мы ответим в течение 10 минут.
Ваша заявка принята!
Рассылка Reconcept, подпишитесь на наш полезный блог
Ваша заявка принята!